Nyoba LLM
Deskripsi
Entah si pengen nyoba aja.
Disclaimer
Tulisan ini saya buat untuk dokumentasi belajar pribadi setelah membaca buku “Build a LLM from Scratch” karya Sebastian Raschka. Semua isi saya tulis ulang dengan bahasa sendiri, sebagian kode mengacu pada repo resmi, dengan tambahan komentar dan penjelasan pribadi.Apa itu LLM?
LLM adalah sebuah neural network yang depat memahami, menjawab, dan merespon manusia layaknya teks. Modelnya yaitu deep neural network yang ditrain dengan teks yang jumlahnya sangatlah besar.
Setup
Install python terlebih dahulu untuk windows bisa di https://www.python.org/downloads/, dan untuk code editornya saya merekomendasikan VSCode. Dan di bawah ini adalah extension VSCode yang saya rekomendasikan.
Ada beberapa package python yang perlu diinstall juga, yaitu torch, jupyterlab, numpy, matplotlib, tensorflow, pandas. Untuk cara penginstallannya bebas sebenarnya, dan saya merekomendasikan untuk menggunakan virtual environment (venv) lalu install dengan pip.
Apa sih venv itu? Venv itu berguna untuk membatasi library atau package pyton yang digunakan di dalam folder itu saja. library python sendiri kan bisa diinstall dari banyak macam cara, bisa menggunakan aur, manual, pip, pipx, dan lain sebagainya. Apabila kita langsung menggunakan pip tanpa venv, bisa saja suatu saat saat update sistem atau install package bakal nabrak dengan package lama, nah di sinilah fungsinya venv.
Jadi misal saya punya 2 project, project pertama Computer Vision letaknya di /home/hafizh/project/CV dan project kedua adalah LLM letaknya di /home/hafizh/project/LLM. Misal project CV saya membutuhkan numpy versi 1.25, sedangkan LLM saya membutuhkan numpy versi 2.2. Nah kan bakal nabrak tuh, jadi venv digunakan untuk setiap project atau direktori memiliki installannya sendiri-sendiri, juga biar ga menuh-menuhin kalau misal install langsung semua.
Langsung saja instal uv terlebih dahulu, berhubung saya menggunakan arch maka berikut commandnya
yay -S uvSetelah itu masuk ke direktori project yang diinginkan, di sini saya menggunakan direktori /home/hafizh/project/LLM. Lalu aktifkan venvnya dengan perintah
uv venv --python=3.10Lalu aktifkan dengan perintah
source .venv/bin/activateApabila venv berhasil diaktifkan maka di sebelah kanan ada logo python diikuti nama folder dan versinya seperti berikut.

Setelah itu lanjut ke install packagenya dengan pip, berikut perintahnya.
uv pip install -r https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/refs/heads/main/requirements.txtNah lalu buka jupyter lab.
jupyter labNanti bakal kebuka otomatis localhost:8888 di browser kek gini tampilannya.
Kan ada pilihan notebook tuh, pilih aja yang ipykernel.
Mainan Text Data
Jadi kalau mau bikin LLM itu ada 3 fase, yaitu :
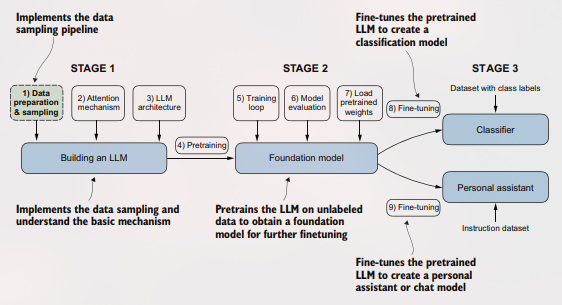
Nah, mainan text data ini ada di stage 1 no 1 yaitu persiapan data dan samplingnya.
Tokenizing Teks
Tokenizing teks itu memecah teks menjadi kata, subkata, atau karakter. Buka jupyterlab yang tadi udah dibuat notebooks. Kita akan mendeklarasikan file The Verdict ke dalam program agar bisa kita lakukan tokenizing.
import urllib.request
url = ("https://raw.githubusercontent.com/rasbt/"
"LLMS-from-scratch/main/ch02/01_main-chapter-code/"
"the-verdict.txt")
file_path = "the-verdict.txt"
urllib.request.urlretrieve(url, file_path)File the verdictnya sudah berhasil kita deklarasikan, jadi nanti tinggal panggil file_path aja klaau butuh. Nah selanjutnya kita akan mencoba untuk menampilkan 200 karakter pertama dari file tadi.
with open("the-verdict.txt", "r", encoding="utf-8") as f:
raw_text = f.read()
print("Total number of character:", len(raw_text))
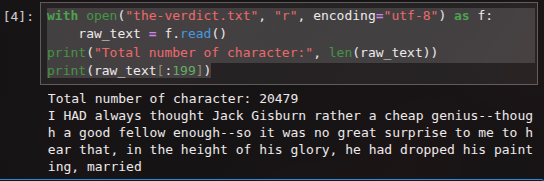
print(raw_text[:199])Kalau udah berhasil, outputnya akan seperti ini.
Nah selanjutnya adalah gimana cara kita buat ngebagi teksnya buat kita lakukan tokenizing? Kita akan mencoba mengilustrasikan sederhana menggunakan program simple dengan library re dengan contoh teks simpel. Berikut contoh programnya
import re
text = "Halo kak. Saya mau beli mi ayam."
result = re.split(r'(\s)', text)
print(result)Dan seperti inilah outputnya :
['Halo', ' ', 'kak,', ' ', 'Saya', ' ', 'mau', ' ', 'beli', ' ', 'mi', ' ', 'ayam.']Setiap katanya sudah berhasil terpisahkan, namun kalau kita perhatikan lebih detail, masih ada kata yang jadi 1 dengan beberapa karakter bukan? Gimana cara agar bisa terpisah?
Dengan cara kita modifikasi bagian re.split-nya, ini bagian untuk ngeformat atau ngatur kata setelah terpisah.
import re
text = "Halo kak, Saya mau beli mi ayam."
result = re.split(r'([.,]|\s)', text)
print(result)Program tsb akan memisahkan titik dan koma. Seperti berikut outputnya :
['Halo', ' ', 'kak', ',', '', ' ', 'Saya', ' ', 'mau', ' ', 'beli', ' ', 'mi', ' ', 'ayam', '.', '']TO BE CONTINUED